안녕하세요, 누리클라우드입니다. 여러 서버들로부터의 로그를 한 곳에서 수집하고 확인해야 하는 경우가 종종 있습니다. 이번 글에서는 Fluentd라는 도구를 이용하여 여러 대의 웹서버로부터 Amazon S3 버킷으로 로그를 수집하는 간단한 방법을 소개해드리겠습니다.
Fluentd
Fluentd는 오픈소스 데이터 수집기로, 데이터의 수집과 분석을 통합하여 보다 유용하게 활용할 수 있도록 해줍니다. Fluentd는 다양한 소스로부터 생성되는 로그 데이터를 JSON 포맷으로 구조화하여 원하는 목적지로 전달합니다.

출처: https://www.fluentd.org/architecture
Fluentd 특징
– 여러 원본 및 대상 서버로부터 데이터를 JSON 형식으로 구조화하고, 모든 형태의 데이터를 통합할 수 있습니다.
– 500개 이상의 커뮤니티가 제공하는 다양한 플러그인이 있습니다.
– C언어와 Ruby로 작성되었으며 시스템 리소스가 거의 필요하지 않습니다.
– 메모리 및 파일 기반 버퍼링을 지원하여 노드 간 데이터 손실을 최소화합니다.
패키지 설치 및 구성
td-agent?
Ruby로 작성된 fluentd를 사용자가 쉽게 사용할 수 있도록 Treasure Data 사에서 배포, 유지보수하고 있는 안정적인 배포 패키지입니다. Ruby Gem 등의 프로그램과 시작 스크립트 등의 편리한 파일을 설치 명령 하나로 제공해줍니다. td-agent는 환경 변수 PATH에 존재하지 않는 디렉토리에 Ruby Gem을 설치 해주기 때문에 전체 시스템에 영향을 주지 않고 사용하는 장점이 있습니다. td-agent와 Fluentd의 차이점은 다음 링크를 참조하세요. https://www.fluentd.org/faqs
td-agent 설치하기
설치 방법 중 RPM 패키지로 설치하는 방법은 아래와 같습니다.
# curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
위와 같이 명령 실행하면 설치스크립트가 자동으로 새로운 RPM 저장소를 /etc/yum.repos.d/td.repo에 등록하고 td-agent RPM 패키지를 설치합니다.
데몬 실행하기
td-agent는 systemd, init.d 두가지 방식의 데몬 기동 스크립트를 제공합니다. 이 중 init.d방식으로 데몬을 기동하겠습니다.
# /etc/init.d/td-agent start
간단한 테스트
간단한 동작 테스트를 위해 /etc/td-agent/td-agent.conf에 위치한 설정파일에서, 지정된 소스 경로에서 HTTP로그를 가져와 로컬파일 /var/log/td-agent/td-agent.log에 저장하도록 구성한 뒤, 웹로그를 한 번 발생시켜 보고 발생된 로그가 지정된 파일로 잘 저장되는지 체크해 봅니다.
# curl -X POST -d ‘json={“json”:”message”}’ http://localhost:80/debug.test
# tail -f /var/log/td-agent/td-agent.log
2018-08-07 15:05:41 +0000 debug.test: {“json”:”message”}
로그가 지정된 경로의 파일에 실시간으로 저장되는 것을 확인할 수 있습니다.
td-agent.conf 수정
이제 아래와 같이 mycompany_weblog S3 버킷에 웹로그가 전송되도록 설정파일를 수정합니다.
<source>
@type tail
@id input_tail
<parse>
@type apache2
</parse>
path /var/log/httpd/access_log
pos_file /var/log/td-agent/apache2.access_log.pos
tag s3.apache.access
</source>
#
<match s3.*.*>
@type s3
#
aws_key_id AKIAXXXXXXXXXXX
aws_sec_key ENxxXXxxXXxxXXxxXXxxxxxXXXX
s3_bucket mycompany_weblog
s3_region ap-northeast-2
path logs/
#
<buffer>
@type file
path /var/log/td-agent/s3
timekey_wait 10m
chunk_limit_size 256m
</buffer>
#
time_slice_format %Y%m%d%H
</match>
<match> 지시자 안에 S3 키/버킷/리전/경로 정보를 입력합니다.
<buffer> type은 파일로 저장되도록 file선택합니다. 미지정시 memory로 기본 설정됩니다.
Path는 버퍼링 파일이 저장될 경로입니다.
Timekey_wait는 버퍼링 된 파일을 s3에서 처리할 시기를 결정한다. 일반적으로 fluentd가 지연된 이벤트를 받을 수 있도록 대기시키는 시간입니다.
output 옵션 및 설정에 대해서는 아래 링크를 참조 바랍니다.
https://docs.fluentd.org/v1.0/articles/apache-to-s3
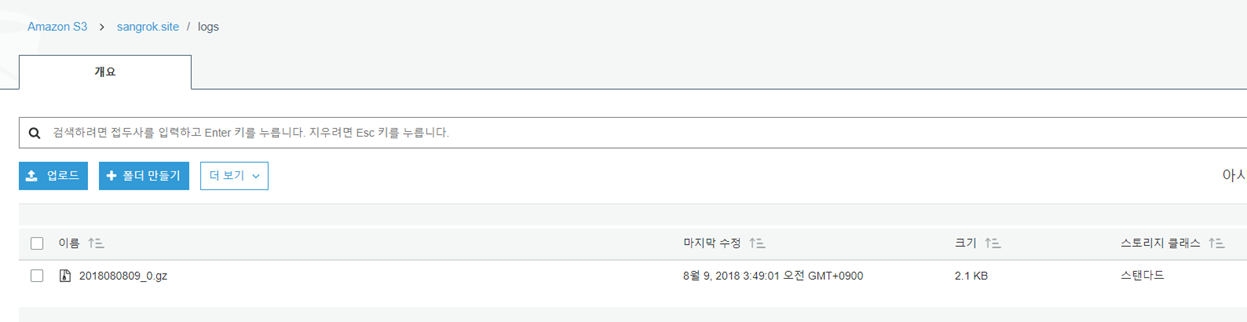
확인
지정한 S3 버킷에 수집된 로그가 아래와 같이 gzip 형식으로 저장되는 것을 확인할 수 있습니다.
참고
실제 서비스 환경에서는 fluentd의 안정적인 동작을 보장하기 위해 서비스 환경에 따라 몇 가지 최적화 설정을 해 줄 필요가 있습니다.
1) 파일 디스크립터 설정 변경
웹호스팅 용도의 서버 등 다수의 로그 파일을 사용하게 되는 환경에서는 fluentd 프로세스가 오픈할 수 있는 파일의 개수 한계를 늘려 주어야 운영 중에 “Too many open files” 에러가 발생하지 않습니다. fluentd의 플러그인과 in_tail의 파일 수, in_forward의 접속 수, buf_file의 버퍼 정크 수 등의 설정에 따라 다르겠지만 65536 정도가 안전합니다.
# cat /etc/security/limits.conf
root soft nofile 65536
root hard nofile 65536
* soft nofile 65536
* hard nofile 65536
참고링크: https://medium.com/hbsmith/too-many-open-files-%EC%97%90%EB%9F%AC-%EB%8C%80%EC%9D%91%EB%B2%95-9b388aea4d4e
2) 네트워크 커널 파라미터 최적화
다수의 대량의 로그가 발생하는 고부하 환경의 경우, 아래 매개 변수를 /etc/sysctl.conf 파일에 추가합니다.
# cat /etc/sysctl.conf
net.core.somaxconn = 1024
net.core.netdev_max_backlog = 5000
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_wmem = 4096 12582912 16777216
net.ipv4.tcp_rmem = 4096 12582912 16777216
net.ipv4. tcp_max_syn_backlog = 8096
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_tw_reuse = 1
net.ipv4.ip_local_port_range = 10240 65535
맺음말
이상으로 Apache로그를 S3버킷에 업로드 하는 간단한 구성을 살펴보았습니다. 이 글에서는 아파치 웹로그를 수집하는 구성 예를 소개 드렸으나 다양한 수집 환경에서 분산된 서버들의 데이터를 S3 버킷에 통합하게 되면 이후 Amazon 서비스와 연계하여 추후 서비스 분석 및 관리가 보다 용이할 것 같습니다.